

Semantic Folding: A Brain Model of Language
The primary acquisition of a 2D-semantic space as a distributional reference for the encoding of word meaning is called Semantic Folding.
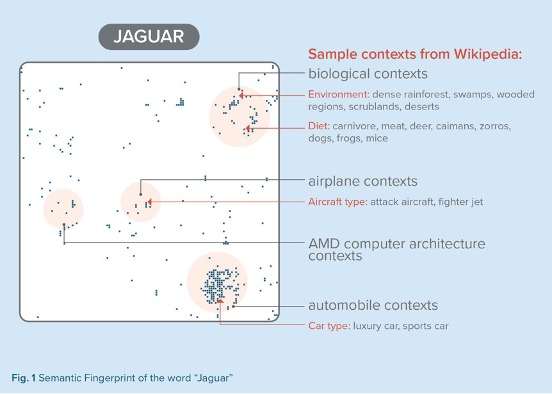
Every word is characterized by the list of contexts in which it appears. Technically speaking, the contexts represent vectors that can be used to create a two-dimensional map in such a way that similar context-vectors are placed closer to each, using topological (local) inhibition mechanisms and by using competitive Hebbian learning principles.
This results in a 2D-map that associates a coordinate pair to every context in the repository of contexts. This mapping process can be maintained dynamically by always positioning a new context onto the map.
This map is then used to encode every single word by associating a binary vector with each word, containing a “1” if the word is contained in the context at a specific position and a “0” if not, for all positions in the map.
After serialization, we have a binary vector that possesses all advantages of an SDR:
- Every bit in a word SDR has semantic meaning.
- If a set bit shifts its position (up, down, left or right), the error will be negligible or even unnoticeable because adjacent contexts have a very similar meaning. This means that word SDRs are highly resistant to noise.
- Words with similar meanings look similar due to the topological arrangement of the individual bit-positions.
- The serialized word-SDRs can be efficiently compressed by only storing the indices of the set bits. The information loss is negligible even if subsampled.
- Several serialized word-SDRs can be aggregated using a bitwise OR function without losing any information brought in by any of the union’s members.
Semantic Folding: how does it work?
The process of Semantic Folding encompasses the following steps:
















